 Hao's learning log
Hao's learning log By graphql.org
By graphql.orgGraphQL at scale: schema stitching v.s. schema federation
I have been helping to lead a GraphQL team at a large organization. The goal of my team is to create a scalable GraphQL platform and increase its adoption within this company. When I joined the team, we'd already gone through several iterations and failed to onboard any consumer in the 1 - 2 year period. The approach at the time of my joining was to use schema stitching with an open-source framework called GraphQL Mesh. After experiencing numerous challenges and we are now shifting to Apollo Federation as an alternative, which as the name suggests federates the schema instead of stitching them. In this article, I will share the differences between these two approaches and walk through my experiences with them including why we making the switch, particularly in regards to scalability and stability.
What is GraphQL schema and why is it important?
A GraphQL schema is a way of defining the types, queries, and mutations that can be used in a GraphQL service. If you are unfamiliar, the closest thing in the REST world is probably an API specification.
Here's an example of what a GraphQL schema might look like:
type Query {
user(id: ID!): User
users: [User]
}
type User {
id: ID!
name: String
email: String
}One could say the GraphQL schema serves as the backbone of a GraphQL API since it defines the structure and shape of the data that can be queried or mutated. The schema act as the contract between the backend and the frontend, which can also be viewed as documentation. With tools such as graphql-codegen, the consumer of a GraphQL service can generate boilerplate code and type definitions from the schema, saving engineers' time and effort.
The single GraphQL service approach doesn't scale
The common implementation of a GraphQL service is to set it up as a layer in front of other data providers, such as API services or databases. All requests from clients go through the GraphQL service in the form of GraphQL operations (queries, mutations, and subscriptions). The GraphQL service then processes these requests and forwards them to the appropriate data providers. Once the data has been retrieved, the GraphQL service touches up the data and returns it to the client. The diagram below for an illustration of this process.
In this setup, often teams follow a BFF (backend for frontend) approach, formatting and tweaking the schema to match the expectations of the consumer.
Initially, teams will start by converting or adding a GraphQL service in front of one existing backend service. Then over time, as it proves to be beneficial, teams will start adding more backend services to the same GraphQL service, as shown in the diagram below.
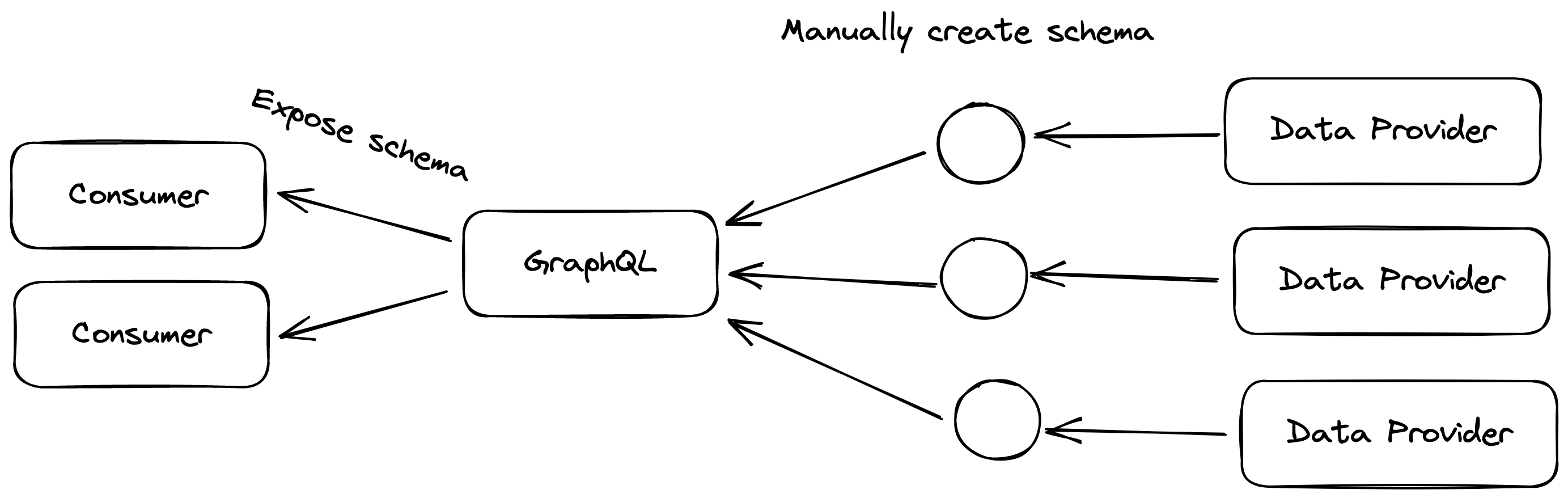
While this approach works well for small organizations with a limited number of data providers, it can become problematic in larger organizations.
- Adding new data providers to the GraphQL service can be time-consuming and error-prone since the schema must be defined manually for each provider.
- Additionally, as the number of data providers increases, the GraphQL service can become a monorepo that slows down development due to its growing internal complexities.
- The GraphQL team can become a bottleneck, as all changes to data providers must be coordinated with changes to the GraphQL schema to ensure that the schema and data responses remain in sync.
In the beginning, the biggest issue for our team was the very first point. There were already many APIs within the organisation which we could integrate with, but it took a long time to get them added to the earlier iterations of the GraphQL service. To workaround this problem, we looked toward adopting the schema stitching strategy that came with GraphQL Mesh. It allowed us to add new data providers more easily by automating the conversion of API specs to GraphQL schemas. GraphQL Mesh also helps to reduce the complexity of coordinating changes between the GraphQL schema and data providers with the help of a service called Hive (we'll touch on this later).
Schema stitching
Schema stitching in essence is the process of combining multiple GraphQL schemas into a single, unified schema that is presented to the consumer. This was a concept initially proposed by Apollo, which they later abandoned and then was picked back up by The Guild who built GraphQL Mesh on top of it. The approach is great if a company is looking to migrate from traditional REST APIs to GraphQL, because with Mesh offers a plug-n-play integration flow, assuming of course each REST API came with API specs (e.g. Swagger, OpenAPI, RAML, etc).
With Mesh, naturally, we adopted its sibling SaSS service Hive as well. Hive, an open-source tool also created by The Guild, is a schema registry with some handy features that synergy well with Mesh or any GraphQL service in general. Hive is a schema CDN, that hosts the latest schema and stores previous versions of the schema. This means it has a historical view of how the schema evolved over time but also offers the ability to track each iteration of the schema on each data source (e.g. REST API). Schema is like a contract, and it is very important for all parties to know when a contract has been broken so it can be quickly fixed. Hive supports the ability to perform schema checks and notify of any breaking changes. We also used the paid feature which allows us to send usage metrics to Hive and see relevant monitoring stats. Hive can then use these usage data to let us know if something is safe to be removed.
After implementing schema stitching, the biggest win for us was how quickly and easily we could add data providers to the GraphQL service. At this point, our architecture looked something like this:
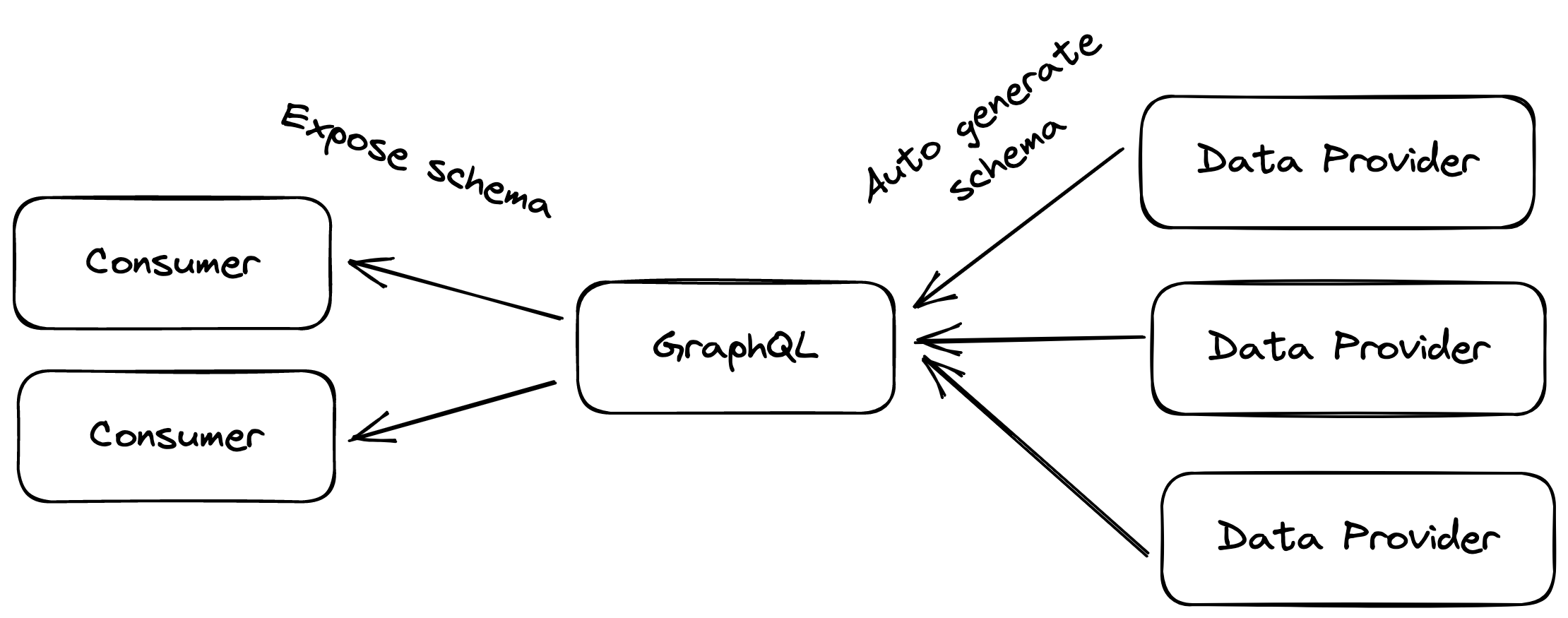
Now, schema stitching wasn't a flawless solution:
- Schema stitching requires accurate and reliable API specifications, unfortunately, most of the REST APIs we were dealing with didn't have good or any API specs. This meant we had to either generate a schema from a raw API response (yes Mesh can do that) or we had to create and maintain the Swagger (or alternative) API specs manually. Both approaches were less than ideal and required massive maintenance effort.
- This is still a monolith solution, the issue mentioned in the previous section still applies here.
- We are still the bottleneck between consumer and data provider teams due to the lack of accurate API specs.
- When an issue occurs, we are the first to get notified but the issue often comes from the underlying data provider.
- A new problem was that Mesh packages are still in pre-stable phase and not following Semantic Versioning, so we often encountered bugs that led to a lot of headaches and slowed down development.
Given the above challenges, we explored alternatives and decided to move to Apollo Federation.
Schema Federation
Schema federation refers to the process of combining multiple individual schemas into a single, federated schema. In a schema federation, each schema retains its structure and integrity, but a new, overarching schema is created that combines the various schemas into a single logical unit. This allows for seamless querying and integration of the different data sources, without the need to manually combine or transform the data.
Using Apollo Federation, you can create a single GraphQL schema that is composed of multiple independent services called subgraphs. This allows you to build complex and powerful GraphQL APIs without having to create a monolithic schema that is managed by a single team or service. Instead, each service can manage its portion of the schema, and the federated schema is built automatically by combining the individual schemas.
Just like Mesh has Hive as its schema registry, Apollo offers its SaSS service called Apollo GraphOS which offers all the features of Hive and more. You can read more about it in Apollo's docs.
How is it different to schema stitching?
In many ways, schema federation has many similarities to schema stitching. GraphQL schema federation and schema stitching are both techniques for combining multiple GraphQL schemas into a single, cohesive schema. However, there are some key differences between the two approaches.
Schema stitching follows a central governance model, where each data provider doesn't need to know about each other. The GraphQL service that stitches all the schema is both the gateway and the brain that decide how schemas get stitched. Federation, on the other hand, has a router service but uses a decentralised governance model. It requires each data source to know about each other and define their relations between themselves.
Schema federation is a built-in feature of the Apollo GraphQL platform, whereas schema stitching is a technique that can be used with any GraphQL implementation. This means that schema federation is designed to be easy to use and integrate with other Apollo tools, whereas schema stitching is a more general-purpose solution that may require more work to set up and use.
Finally, schema federation uses a set of conventions and APIs to define how the individual schemas should be combined, whereas schema stitching typically involves writing custom code to manually merge the individual schemas. This means that schema federation can be easier to use and maintain, especially for large and complex GraphQL APIs, whereas schema stitching can be more flexible and allow for more customization.
How we use schema federation
With Federation, our new architecture now looks something like the following diagram.
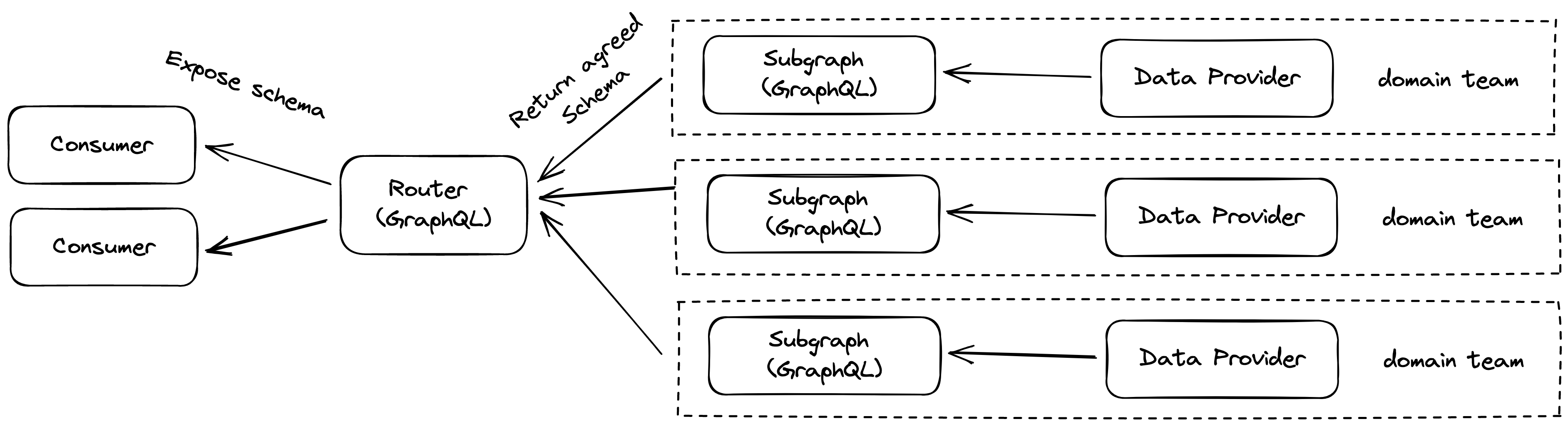
The idea is to have a separate team manage a single subgraph and its data provider(s). We then took this idea further by making these teams into domain-based backend teams, who are responsible for the domain subgraph and the data providers (in our case they are mostly REST APIs).
Which is the right one for you?
As mentioned already, we decided to ditch schema stitching and migrate over to federation. Partly because our current data providers (REST APIs) have room for improvement. As part of the migration, we are going to rewrite the current APIs into domain APIs with GraphQL subgraphs in front of them. The wider business decision to move to a domain-driven backend has very good synergy with Apollo Federation. Of course, these are probably unique to our situation and others may not be so lucky. So let's discuss some common pros and cons of each approach.
Benefits of schema federation
There are several other benefits to using schema federation over schema stitching when building a distributed GraphQL schema. Some of the key benefits include:
- Convenience: Schema federation is a built-in feature of the Apollo GraphQL platform, so it is easy to use and integrate with other Apollo tools. This means you can quickly and easily create a federated schema without having to write a lot of custom code.
- Maintainability: Schema federation uses a set of conventions and APIs to define how the individual schemas should be combined, which makes it easier to maintain and update the federated schema over time. This can be especially helpful for large and complex GraphQL APIs.
- Compatibility: Schema federation is fully compatible with the Apollo Client and other popular GraphQL tools, so you can use it to build rich and powerful GraphQL-powered applications.
- Performance: Schema federation is designed to optimize performance and minimize network overhead, which can be important for large and complex GraphQL APIs.
- Stability: From our testing Apollo software is more stable and mature compared to GraphQL Mesh which is the main if not only schema stitching tool out there.
Benefits of schema stitching
There are several benefits to using schema stitching over schema federation when building a distributed GraphQL schema. Some of the key benefits include:
- Flexibility: With schema stitching, you have complete control over how the individual schemas are combined. This allows you to customize the schema stitching process to fit the specific needs of your application.
- Compatibility: Schema stitching can be used with any GraphQL implementation, whereas schema federation is only available on the Apollo platform. This means that schema stitching may be a better option if you are using a different GraphQL implementation or if you want to use a mix of different GraphQL implementations in your schema.
- Customization: With schema stitching, you can write custom code to merge the individual schemas in any way you want. This allows you to add custom logic and behaviour to the schema stitching process, which can be useful for complex or specialized GraphQL APIs.
- Open source: all Mesh code is open source, so anyone could see and fork them as they see fit. The Guild even said they'll be making Hive (schema registry) open source as well.
Conclusion
Choosing the approach is important, but it is also worth thinking about the tools behind them as well. From our research, if you want to go with schema stitching then GraphQL Mesh is the only implementation right now, and similarly Apollo Federation is the only choice if you pick schema federation. While GraphQL Mesh gets additional points for being open source, it is still a few steps behind Apollo both in terms of scale and software maturity. For example, many of the Mesh packages are still not following Semantic Version at the time of writing, however, based on their roadmap this might not be the case for long. Until then, Apollo might be the better choice for teams wanting a stable platform to build their GraphQL services.
As mentioned in the "How is it different to schema stitching?" section, the two approaches use different governance models. If you work in a large company, then I would suggest Federation because sooner or later you will reach a point where a single GraphQL team isn't enough to provide support, maintenance and development to meet the demand from all the consumers and data providers. Handling schema changes is not only time-consuming but requires careful coordination, in my team we found ourselves spending a decent amount of time preventing breaking changes and supporting new schema releases. In smaller companies or even medium-sized companies (several consumers and data providers instead of tens or even hundreds), schema stitching provides more flexibility and be more easily slotted into an existing REST backend architecture.
Ultimately, the choice between schema stitching and schema federation will depend on the specific needs of your application, so it's important to evaluate both options and choose the one that best fits your requirements. This is the perfect situation to create PoCs and test out each approach before committing.
